20 September
Best Practices for Implementing and Designing a REST API
Design
Programming
Web apps
min. read

REST stands for an architectural approach to designing web services and became the standard for applications to communicate and exchange data due to their simplicity as well as scalability, but the fact is – designing a REST API is still challenging.
How to create REST APIs properly aforetime in order not to have any architectural problems on the way of designing? You probably know that this can affect the whole infrastructure.
In this guide, we will shortly (but precisely) describe some of the best practices when designing and implementing REST APIs, along with a few code examples.
3 common characteristics of an effective API design
We can distinguish the features of the API that make it a success. Firstly, it could be easy to use and work with, secondly – hard to misuse, and lastly – complete and concise. Taking into consideration all of the above points, we can prepare principles that will ensure these features. Let’s skip into them.
NAMING
- Use nouns for resources
While defining an API endpoint, you should always use nouns to represent resources, not verbs. So here, for example, we are using items and users instead of createitems and newusers.
example.com/v1/store/items/{id}
example.com/v1/store/users/{id}- Use logical grouping by reflecting relationships between objects
When designing endpoints, it’s also a great idea to leverage logical grouping, which means, if one object may contain another object, the best option is to design the endpoint to reflect that. This is a good practice regardless of whether the data is structured that way in the database. If we want the endpoint to get orders for a customer, we need to append the /orders path to the end of the /customers.
It’s a wise idea to avoid reflecting the database structure with APIs to prevent passing unnecessary information to any attackers. You might as well go in the other direction and represent the endpoint from the order back to the customer using a URL like /orders/67/customers. Nevertheless, extending this model too far can get problematic to implement. In this case then, the solution is to ensure navigable links to related resources.
- Use pluralized nouns for resources
When specifying endpoint names, use plural nouns for resources, such as items and users instead of item and user.
- A collection is a group of resources
Simply saying – a resource contains data and relationships with other resources. Collection is a group of resources, for example, /orders is a collection of orders and /orders/67 is a resource having information about a specific order. Remember to avoid complex URLs. Don’t go further than collection/resource/collection.
- Enhance readability by using hyphens & version your API
Instead of an underscore, you can use a hyphen inventory management. Also, don’t forget to correctly version your API. It’s a great practice from the beginning to prevent breaking changes for your clients when updating an API. Changing one little detail in the URL, name or response can cause breaking dozens of applications. Fortunately, you can always easily add a version path to the endpoint, such as example.com/v1/store and so on. Optionally, instead of providing multiple versions of the URL, you can specify the version of the resource by using a parameter in the query string enclosed in the HTTP request – example.com/store?version=2.
PROPER USING OF HTTP METHODS
Each HTTP method has a specific purpose, and their proper use is critical to an API that is easy to understand and operate.
- GET – retrieve a resource or collection of resources
- POST – create a new resource
- PUT – update a resource
- DELETE – delete a resource
For fetching a list of users, the API endpoint is: GET: /users
For creating a new user: POST: /users
HATEOAS
Hateoas stays for Hypertext as the Engine of Application State. This is a principle that enables navigation through your API via hyperlinks without prior knowledge about URI scheme. It can make your API easier to understand and use.
Each HTTP get request returns information to find resources connected to the requested object via hyperlinks. The response also carries information describing the operations available for each resource. For example, the provided below JSON response may be from an API such as HTTP GET.
http://api.domain.com/management/departments/20/employees
{
"departmentId": 20,
"departmentName": "Administration",
"locationId": 1700,
"managerId": 200,
"links": [
{
"href": "20/employees",
"rel": "employees",
"type" : "GET"
}
]
}In this example, the response the server returns includes hypermedia links to employee resources 20/employees, which can be browsed by the client to view the employees – members of the department. The great feature of such an approach is that the hypermedia links returned from the server control the state of the application, not vice versa.
JSON has no widely accepted format for representation of links between 2 resources. We can choose to send links in the body of the response, or we can choose to send links in the HTTP response headers:
HTTP/1.1 200 OK
...
Link: <20/employees>; rel="employees"Both methods are great.
FILTERING / SORTING / PAGINATION
- Filtering data by particular key-values
We should not assume that we are able to return all the information in one go, because the database behind the API can be huge. That is why we need methods to filter items by serving query parameters with specific key-value pairs, such as surname value and age value:
/customers?lastname=Swanson&age=37- Fetching only particular fields by key
This approach can be extended. The goal is to limit the field returned for each item if each item contains a high volume of data. As in, not fetching all database columns. You could use a query string parameter, which accepts a comma delimited list of fields such as a product ID or quantity:
/customers?fields=projectID,quantity- Limiting the number of items for the data returned
The important thing is to paginate our data, that is, requesting particular chunks at a time so as not to burden the database or services with requests for all the data.
/customers?limit=100We can accept the limit query parameter and return a certain number of results that was specified.
- Paginate the data chunk by chunk instead of querying all at once
For pagination of the results, which means getting the next chunk, the user will have to provide the updated value along with the limit.
/customers?start=0&limit=50
/customers?start=50&limit=100Filtering and pagination certainly improve the performance of our queries, so it’s always a good idea to keep them in mind.
- Sorting the data by a specified key-value
In addition, we can allow specifying fields for sorting in clear strings. We can get a parameter from the query string with the field for which we want to sort the data.
/customers?sort=author&datepublishedWe can then sort them by these individual fields, for example:
/customers?sort=+author,-datepublishedNote: some older web browsers and proxies won’t cache responses to tasks that include a query string in the URI.
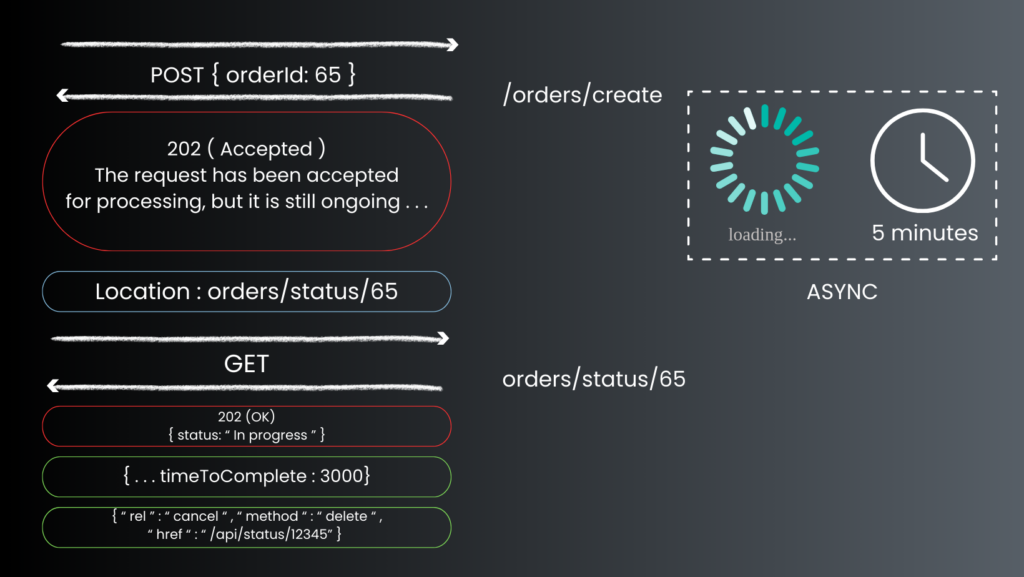
ASYNC OPERATIONS
It happens that a POST, PUT, PATCH or DELETE operation may require a process that takes some time to complete. If you wait for it to finish before sending the response to the client, it may cause an unacceptable delay.
So just consider performing the operation asynchronously. Simply return HTTP status code 202 to indicate that the request has been accepted for processing, but has not been completed. You should also disclose the endpoint that returns the status of the asynchronous request so that the client can track the status by pulling the status endpoint. Also, you should include the URL of the status endpoint in the 202 response location header. If the client sends a get request to this endpoint, the response should include the actual status of the request. It can also contain an estimated time to completion or a link to cancel the operation.
ERROR HANDLING / STATUS CODES
The crucial element in working with API is to provide meaningful error messages and use appropriate status codes to help clients understand what is wrong.
Error codes must have messages assisting them so that the developers have enough information to unravel the issue, but attackers can’t use error code content.
Some common HTTP status error codes can be:
- 400 bad request – the server could not understand the request due to malformed syntax;
- 401 unauthorized – the request requires user authentication;
- 404 not found – the server couldn’t found anything matching the request-URI;
- 408 request timeout – the client didn’t produce a request within the time the server was prepared to wait;
- 500 internal server error – the server met an unexpected issue, which blocked fulfilling the request;
- 502 bad gateway – server, operating as a gateway or proxy, received an invalid response from the upstream server it was accessing in an attempt to fulfill the request;
- 503 service unavailable – the server is currently not available to handle the request, because of the temporary overloading or maintenance of the server.
Note: remember to implement the proper HTTP status code though, because there are tons of them and the exact handling can also depend on the design of the particular API.
SECURITY OF YOUR API
With reference to security, it is worth highlighting a few points in particular to keep in mind.
- Authorization
It refers to the process of specifying what permissions an authenticated user has (what actually they can do). This is one of the key aspects of API security because it restricts access to resources based on a user’s privileges. Typical authorization strategies include role-based access control (RBAC) and attribute-based access control (ABAC).
- Set SSL/TLS encryption as default for API endpoints
When applied to API endpoints these protocols encrypt the data transmitted between the client and server, ensuring that attackers can’t read or modify the data during transmission. Setting SSL/TLS encryption as the default ensures that all data sent through the API is secure.
- Implement ACLs (Access Control List)
This is a list of permissions attached to an object. It specifies which users or system processes are granted access to objects, as well as what operations are allowed on given objects. Implementing ACLs in the context of API security helps in fine-tuning the access permissions, effectively preventing unauthorized access to your API.
- Rate limiting / throttling / IP blacklisting
These are techniques used to control the amount of traffic an API user can send during a specific period.
- Rate limiting sets a limit on the number of API calls a user can make in a particular time.
- Throttling reduces the speed of API response.
- IP blacklisting blocks requests from certain IP addresses.
These methods can prevent abuse, protect your API from DoS (Denial of Service) or DDoS (Distributed Denial of Service) attacks, and ensure fair usage.
- Preventing XSS
XSS is a type of security vulnerability typically found in web applications. It allows attackers to inject malicious scripts into web pages viewed by other users. To prevent XSS attacks in APIs, you should encode your output, validate and sanitize your input, use HTTPOnly cookies, and implement Content Security Policy (CSP).
DOCUMENTATION
Last thing, but very important to remember – keep your documentation up-to-date. It should include all endpoints, request examples, error messages and other.
Some helpful tools to achieve this: Postman, Swagger UI (OpenAPI), Apiary, Git version control system, ReadMe, Docusaurus, Redoc or Slate.
These are only some examples, but no matter what tool you will use, the crucial is to have a process in place ensuring that the documentation is updated right after any changes are made.
SUMMARY
We’ve reached the summary. The presentation of the above elements is still something that can be further developed, but here we have gone through very key elements leading to the help in designing and implementing a REST API that is robust, easy to use and scalable. Practices mentioned above lead to keeping your API as simple and intuitive as you want it to be.


About prog
Founded in 2016 in Warsaw, Poland. Prographers mission is to help the world put the sofware to work in new ways, through the delivery of custom tailored 3D and web applications to match the needs of the customers.
SIMILAR POSTS
How to Achieve CG Photorealism – Basics & Tips
3D
Design
min. read
Deploying Nginx as an API Gateway – Tips & Functionalities
Programming
Web apps
min. read
8 UI/UX Best Practices for the Successful Performance of the Website
Design
Web apps
min. read
Let's talk
I agree that my data in this form will be sent to [email protected] and will be read by human beings. We will answer you as soon as possible. If you sent this form by mistake or want to remove your data, you can let us know by sending an email to [email protected]. We will never send you any spam or share your data with third parties.
I agree that my data in this form will be sent to [email protected] and will be read by human beings. We will answer you as soon as possible. If you sent this form by mistake or want to remove your data, you can let us know by sending an email to [email protected]. We will never send you any spam or share your data with third parties.