23 May
List vs Dictionary performance
Programming
min. read
Premature optimization is the root of all evil
I would argue that premature optimization is the root of all evil. Especially overengineered optimization that prevents further extension of the system is bad. On a low level as programmers, we always think about whether use an Array or List or Dictionary (HashSet) as a data structure for our given case.
Unfortunately, there is no one size fits all, use case but we often see that “maybe if I put a dictionary here my code will be faster” and without much thought, we go for dicts.
Testing method
I have used C# to conduct this test, as this is the language I’m the most familiar with, and below you can find my testing method
- BenchmarkDotNet
- Bench Settings:
launchCount: 3, warmupCount: 3, targetCount: 10 - Spec: Processor i7 4790k, 32GB RAM
- Collection sizes N – 10, 100, 1000, 10000, 100000
- Samples 0.002 = 1, 1, 2, 20, 200
- All times presented are in
ns - Tested:
- List<Foo>
- Dictionary<int, Foo>
- Dictionary<string, Foo>
- Foo class
public class Foo
{
public int Index { get; set; }
public string Name { get; set; }
public Vector3 StartPosition { get; set; }
public Vector3 MiddlePosition { get; set; }
public Vector3 EndPosition { get; set; }
}
public struct Vector3
{
public float X;
public float Y;
public float Z;
public Vector3(float x, float y, float z)
{
X = x;
Y = y;
Z = z;
}
}For this test, I have used a pretty simple class that had what I needed for the test. I needed an int field Index that would simulate index in the list access as well as potential access via reference. I have also added Name that represents access via string which is also a common cause.
Results List vs Dictionary
The first and most common use case is to access the list by Index, so I implemented what that could look like when using a similar dictionary.
In the tests, you can find a distinction between Single and Multiple access.
Single means that a given code requested a single index or value from an increasing size N from a collection.
Multiple means that a given code requested P values (samples) from a collection of size N.
By index results
Access to the list was performed using List[ToFindInt[i]] which would utilize this collection type to its limit. Integer dictionary used to access by Key so it’s also should be fast IndexDictionary[value] And finally, String dictionary used was accessed by the Find method StringDictionary.Values.First(v => v.Index == ToFindInt[i]).Value
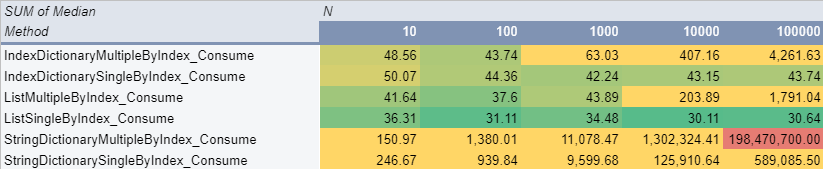
As you can see from those results as we expected, access to the single element was pretty consistent for List and Int Dictionary. Unsurprisingly though access by indexer in the list is around 50-100% faster than access by a Dictionary.
By string results
Access to the string was done via the Find function for the List List.Find(foo => foo.Name == ToFindString[i]) and for Dictionaries the methods used were the same as above but in a different order. String Dict, used StringDictionary[value] and Find for IndexDictionary
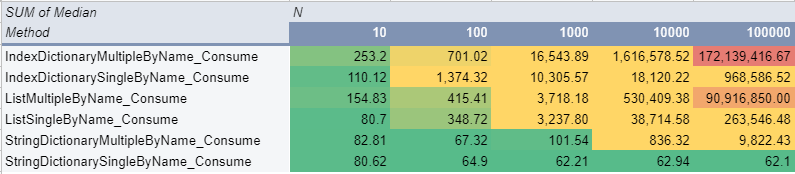
Now unexpected results! Because of String comparison with List – we were limiting list performance because it needed to iterate over the whole list (Optimistic) until an element was found. Which turns out is a lot of time.
You could expect that List for a small number of elements, let’s say 1000, would just zip right through the array and get your result as fast as the dictionary. But it didn’t! The list is slower in order 2x, 6x, 36x, 634x, and over 9000! times slower. This is massive! If someone argues with you that it’s not worth additional memory consumption because performance would be marginal, tell them they are wrong by linking them this article 🙂
Memory pressure
I have used dotMemory to test the memory consumption of the indexes generated and the size of the collection in the memory for 1000 items in the collection.
For reference, the single instance of Foo is between 80B and 82B
Excluding objects themselves, the size of the collections is as follows with all the data inside for the dictionary.

- List
– 3,6kB - 1000x – 4B – the reference to the object
- 1x – 32B array size and version fields
- Dictionary
- 1000x
- 4B – hashCode of the key
- 4B – next pointer
- 4B – the reference to the key
- 4B – the reference to the value
- 4B – corresponding bucket value
- 1x – 80B internals of the dictionary
- 1000x
- Dictionary
- The same string dictionary but instead of the reference to the key – it stores the actual key
The memory pressure is 6x times higher than the simple list, but as you might have noticed, the actual additional data that is stored by the dictionary is reasonable, accounting for a significant boost in the performance.
You might think, right now, that 21kB is way too much. But consider this. We might have text-heavy data where a single object weights 5kB (strings adds up quickly) so for 1000 objects including the size of the collection with the size of the data we got.
- Dictionary 5021kB vs List 5004kB which has an actual difference of only 0.3%
When to use Lists and when Dictionaries
Personally, I would use Dictionaries in all critical path scenarios where we cannot get value by index. Yes all of them!
So where is the place for List/Array?
- When we only care about iterating over the whole collection.
- When we can access data by already known
intindex - When we are absolute, 100% sure that we will have less than 10 objects.
- When we store small objects (below 20B) and memory usage is more important than performance.
Conclusion
What do some smart people keep saying, if you are unsure about results? Test them! 1 hour spent benchmarking a critical path would save hours or even days for the whole development team to optimize and maybe refactor the system to be more optimized.
If you have any questions about this article please leave us a message! We would love to answer the questions 🙂


About prog
Founded in 2016 in Warsaw, Poland. Prographers mission is to help the world put the sofware to work in new ways, through the delivery of custom tailored 3D and web applications to match the needs of the customers.
SIMILAR POSTS
Programming as a Backstage of VR Development
3D
Design
Programming
min. read
Digital twin app – what benefits do digital twin apps offer?
Business
min. read
Unity UI Toolkit is better than expected
Programming
min. read
Let's talk
I agree that my data in this form will be sent to [email protected] and will be read by human beings. We will answer you as soon as possible. If you sent this form by mistake or want to remove your data, you can let us know by sending an email to [email protected]. We will never send you any spam or share your data with third parties.
I agree that my data in this form will be sent to [email protected] and will be read by human beings. We will answer you as soon as possible. If you sent this form by mistake or want to remove your data, you can let us know by sending an email to [email protected]. We will never send you any spam or share your data with third parties.